![]()
Open-Source Seismic Hazard Analysis (OpenSHA)
Overview
What is Seismic Hazard Analysis?
The goal of Seismic Hazard Analysis (SHA) is to state the probability that something of concern will occur given one or more earthquakes. More specifically, SHA states the probability that an Intensity Measure Type (IMT) will exceed some Intensity Measure Level (IML). For example, one might want to know the probability that Peak Ground Acceleration (the IMT) will exceed 0.5 g (the IML).
More information is available in this short primer on PSHA (although this uses old nomenclature).
Basic Model Components
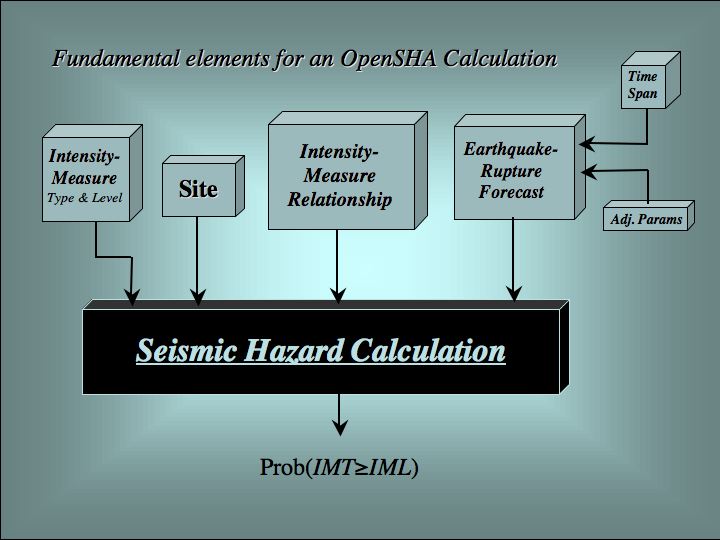
There are two main types of model components in OpenSHA:
Earthquake Rupture Forecast (ERF)
This gives all possible Earthquake Ruptures and their associated probabilities of occurrence in a region and over some time span.
Intensity Measure Relationship (IMR)
This gives the conditional probability that an IMT will exceed an IML at a Site, given the occurrence of a specified Earthquake Ruptures.
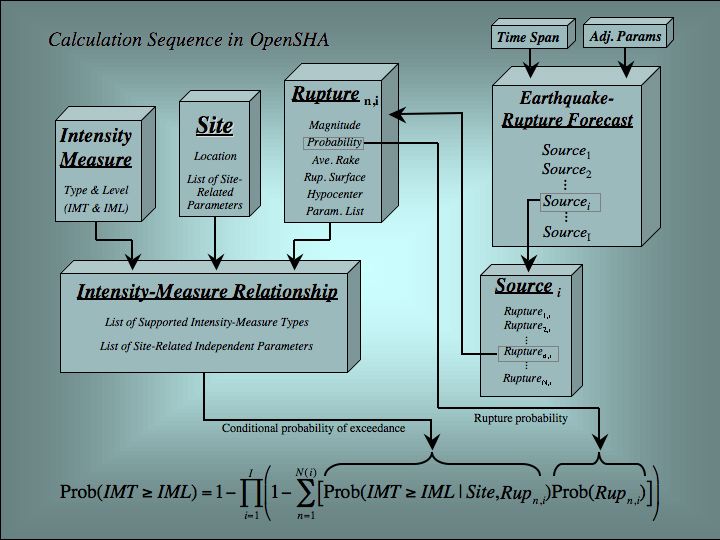
The components and the probabilistic SHA calculation are depicted graphically in the following:
| Basic Components | Computation Details |
|---|---|
 |
 |
{kind=link}
{kind=link}
Note that the definition of an IMR is flexible enough to accommodate both empirical Attenuation Relationships, and more complex models based on, for example, 3D waveform modeling from first principles of physics coupled with nonlinear dynamic structural response calculations. Such generality is an underpinning of OpenSHA, the intent being to accommodate both near- and long-term goals.
A wide variety of ERF and IMRmodels have been, and will continue to be, developed. This diversity reflects differing opinions about how to best model earthquake processes and structural response. Having a variety of viable models is not a conceptual problem in SHA, as the probabilistic formalism includes explicit ways of dealing with differing expert opinion. In fact, proper SHA requires that all viable models be accounted for. This presented a practical problem in the past in that we lacked the computational infrastructure necessary to accommodate the wide variety of models under development. In fact, the level of model sophistication was often constrained by the structure of available SHA codes.
The primary goal of OpenSHA has therefore been to develop an object-oriented infrastructure where any arbitrarily complex model may be implemented. In addition, OpenSHA strives to leverage distributed computing resources that reduce maintenance overhead by authors of complex models and components and offloads processor intensive tasks from local applications.
Modular Framework
Developing desktop and distributed applications requires having a well-established, stable, and modular framework (a specification of the various model and data components and the communication protocol for each). This has been achieved by adopting an object-oriented framework. Because the different disciplines contributing to SHA often hold different meanings for the same word, also important is establishing a fixed vocabulary. For example, “earthquake” literally means earth shaking, but to some it refers to fault rupture (as in an “earthquake catalog” where no information about ground shaking is contained). Although humans can understand such difference contextually, computers communicating with each other cannot.
A manuscript describing the OpenSHA object-oriented framework, including object definitions and the mathematical details of the SHA calculations, has been published in Seismological Research Letters (see Field et al., 2003).
One can also find definitions in the OpenSHA Glossary.
Framework Implementation
The core OpenSHA framework is implemented in the Java programming language. Java was chosen because it meets our requirements of being object oriented, platform independent, web enabled, and potentially distributed over the internet. However, there is nothing language specific about our framework. In fact, several data and/or modeling components are implemented in other programming languages, either out of computational efficiency or to avoid rewriting well-established “legacy” code. Such components are “wrapped” with an appropriate Java interface so they can plug into the OpenSHA framework.
Code Verification
This involves demonstrating that our code does what we intend it to. One advantage of an object oriented framework is that each component can be tested separately (which is what we do, often using the formal Java Junit testing framework). We are also participating in the Pacific Earthquake Engineering Research center (PEER) probabilistic SHA validation working group, which is comparing results from a variety of codes and for a variety of carefully defined test problems. Not only are we implementing these test cases, but we are doing so in way that anyone can set up and run these tests using our applications. Finally, our calculations are compared with those of others (e.g., from the USGS National Seismic Hazard Mapping Program) whenever possible. All code verification is discussed in the documentation associated with each model component or application.
Advanced Information Technologies
We are benefiting immensely by participation in the SCEC Community Modeling Environment. The capabilities enabled by this interaction include:
- Use of distributed object technologies, which enable the various components to exist anywhere on the internet. This is exemplified in the SHA calculations of Field et al. (2005a); these technologies are discussed more generally in the companion paper of Maechling et al. (2005).
- Use of GRID Computing, where run times are reduced by distributing the computational burdon among any available, idle computers on the network. This is exemplified in the SHA calculations of Field et al. (2005b), and the technology is discussed in more detail in the companion paper of Maechling et al. (2005b).
Copyright ©2026 University of Southern California. All rights reserved. License—Disclaimer
This website is generated automatically from the OpenSHA wiki on GitHub, and is powered by GitHub Pages, Jekyll, and this GitHub Action.